Wie gut sind die Prognosen der Umfrageinstituten? Kurz gesagt: Solala. Betrachtet man die jeweils letzten Umfragen vor den vergangenen vier Bundestagswahlen, zeigt sich, dass es deutliche Unterschiede bei der Vorhersagegenauigkeit der Demoskopen gibt. (Richtigerweise muss man sagen: Es handelt sich nicht um Prognosen oder Vorhersagen im eigentlichen Sinne – die Umfragen sollen Abbild einer politischen Stimmung sein.) Update: Dank eines Hinweises von @zoonpolitikon sei hier noch auf die Fehlertoleranz/ Standardabweichung aufmerksam gemacht. Die Zahlen der Umfrageinstitute lagen meist innerhalb der üblichen +/- 2,5 bis 3 Prozentpunkte. Mehr dazu hier.
Durch die Bank weg haben alle der sechs hier betrachteten Umfrageinstitute bei der Wahl in 2005 deutlich daneben gelegen: CDU/CSU sahen alle bei 41 oder 42 Prozent – tatsächlich kamen die auf 35,2 Prozent. Anderseits lag Forsa im Jahr 2002 deutlich näher als die anderen Institute am Endergebnis: Mit insgesamt nur 2,7 Prozentpunkten Abstand. Bei der Bundestagswahl 1998 war Allensbach noch besser: Insgesamt lag man nur 2,4 Prozentpunkte vom Wahlergebnis weg.
Betrachtet werden bei diesem Vergleich die Zahlen für die Parteien im Bundestag (CDU/CSU, SPD, Grüne, FDP, Linke/PDS). Die Abweichung der Vorhersage für jede Partei – egal ob positiv oder negativ – wurden zusammengezählt. So ergibt die Gesamtabweichung beim folgenden Beispiel 6,4 Prozentpunkte.
Die letzten Umfragergebnisse der Institute vor der jeweiligen Wahl wurden bei wahlrecht.de gefunden. Hier die Datei mit den Umfrageergebnissen pro Partei und Wahl bei Google Docs.
Im Überblick ganz oben ist zu sehen, dass Allensbach und Forsa zumindest bei zwei von vier Wahlen die genausten Prognosen gebracht haben. Mal sehen, wie richtig sie am Wahlabend im September liegen. Wenn die Vorhersagen so fehlerhaft sind wie 2005, könnte der Wahlabend doch spannend werden.
—
Siehe die Kritik an diesem Beitrag: „Was Wahlumfragen (nicht) sagen“
und auch: „Warum Wahlprognosen mehr können als Umfragen – am Beispiel Hamburg-Mitte“ bei hamburger-wahlbeobachter.de

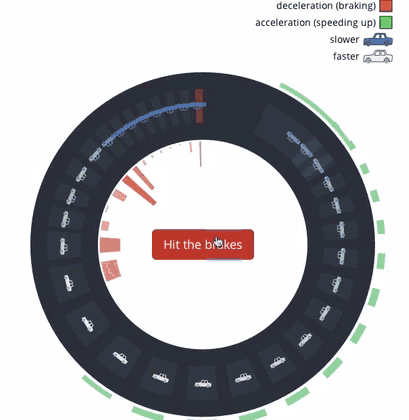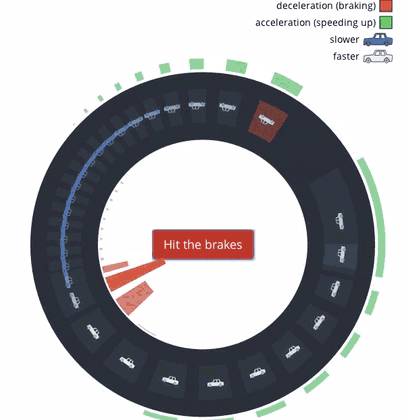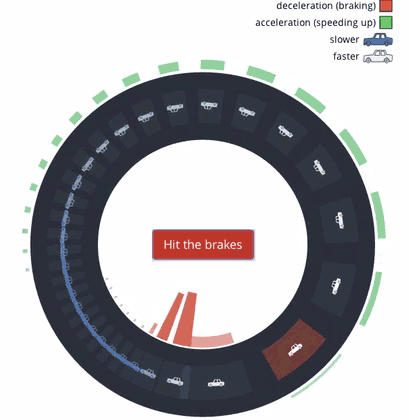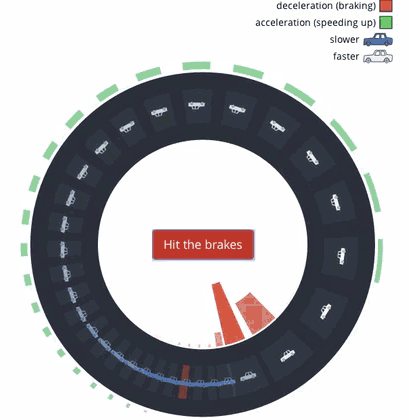
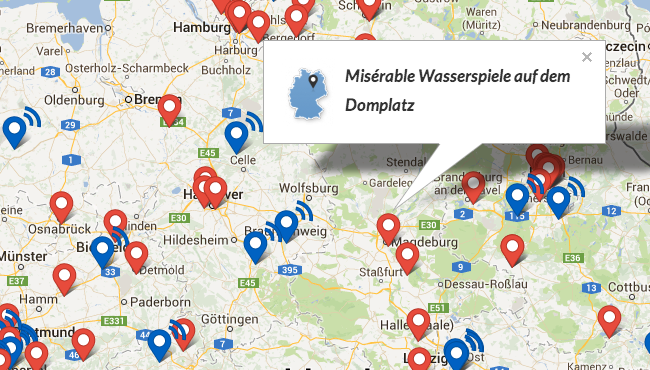 „Verschwendungsatlas“ des Bundes der Steuerzahler
„Verschwendungsatlas“ des Bundes der Steuerzahler